

MetalRT Brings the First Unified AI Inference Engine to Apple Silicon
Artificial intelligence is rapidly moving beyond cloud servers and into the devices people use every day. Laptops, smartphones and edge systems now have enough computing power to run sophisticated models locally, promising faster responses, greater privacy and independence from remote infrastructure. A new inference engine called MetalRT, developed by RunAnywhere (YC W26), aims to accelerate that transition by delivering a complete on-device AI runtime for Apple Silicon that supports three major AI modalities: language models, speech recognition and speech synthesis.
The system combines large language model inference, speech-to-text and text-to-speech into a single runtime optimized specifically for Apple hardware. MetalRT consistently outperforms existing inference frameworks, including Apple’s own MLX, across every workload tested. The result is a platform capable of running multimodal AI pipelines entirely on-device at speeds previously associated with cloud systems.
A Unified Engine for Multimodal AI
Modern AI applications rarely rely on a single capability. Voice assistants, AI copilots and autonomous agents typically require several components working together. Speech recognition is used to interpret spoken input, language models process intent and generate responses and speech synthesis produces natural voice output.
Historically, developers have had to combine several different frameworks to build these pipelines. One runtime might handle speech recognition while another manages language models, which introduces complexity and additional overhead. MetalRT attempts to remove that fragmentation by integrating these capabilities directly into a single engine.
By controlling the entire inference stack, RunAnywhere says it can deliver faster performance
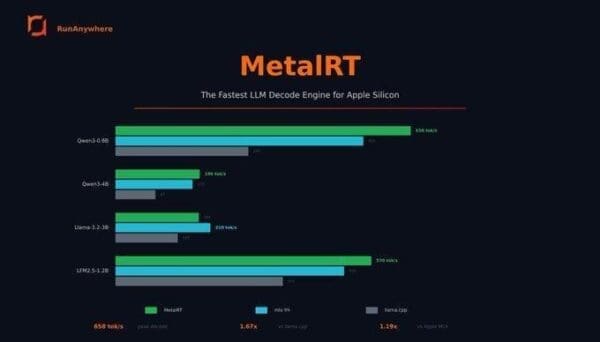
High-Speed LLM Inference
MetalRT originally launched as a high-performance runtime focused on large language models. The system achieves decoding speeds of 658 tokens per second on a single Apple M4 Max chip.
This performance is roughly 1.67 times faster than llama.cpp and approximately 1.19 times faster than MLX using identical models and hardware configurations. With the addition of speech processing capabilities, MetalRT now covers the full set of building blocks required for voice-enabled AI systems.
Accelerating Speech Recognition
Speech-to-text performance was evaluated using Whisper Tiny (4-bit) models across different audio durations. In tests using short four-second audio clips, MetalRT completed transcription in 31.9 milliseconds. The same workload took 42.1 milliseconds using mlx-whisper and 64.9 milliseconds with sherpa-onnx.
As audio length increased, the performance advantage became significantly larger. A seventy-second audio clip was transcribed in just 101 milliseconds, compared with 463 milliseconds using MLX and 554 milliseconds using sherpa-onnx. This corresponds to a real-time factor of 0.0014, meaning the system processes audio roughly 714 times faster than real time.
In practical terms, an hour-long podcast could be transcribed in approximately five seconds, while a three-hour meeting recording could be processed in around fifteen seconds. This represents about a 4.6× performance advantage over Apple’s MLX framework when running identical models.
Faster Text-to-Speech for Voice Interfaces
MetalRT also includes accelerated text-to-speech using the Kokoro-82M model. Voice assistants require extremely low synthesis latency to maintain natural conversational flow. Even modest delays can make responses feel slow or disconnected.
In testing, MetalRT generated speech for a four-word response in 178 milliseconds. The same workload required 493 milliseconds using mlx-audio and 504 milliseconds using sherpa-onnx.
Longer responses showed similar improvements. A ten-word phrase was synthesized in 230 milliseconds compared with 522 milliseconds using mlx-audio. An eighteen-word response required 381 milliseconds compared with 600 milliseconds, while a thirty-six-word phrase was generated in 604 milliseconds versus 706 milliseconds.
Across these workloads, MetalRT delivered roughly 2.8 times faster performance than Apple’s MLX-based text-to-speech implementation. Earlier benchmarks on an Apple M3 Max chip showed latency of about 291 milliseconds for short phrases, enabling what developers describe as near-instant speech responses.
Why a Unified Runtime Matters
The significance of MetalRT extends beyond individual benchmarks. The engine consolidates multiple AI capabilities into a single optimized runtime. Most modern AI systems require speech recognition, reasoning and speech generation working together. Traditionally, each step introduces additional latency and complexity as data moves between different frameworks. By integrating all three modalities directly into one engine, MetalRT reduces overhead and enables fully local AI pipelines that operate in real time.
This architecture could be particularly useful for voice assistants, AI copilots, accessibility technology, translation systems, and real-time transcription platforms. Because the entire pipeline runs locally, sensitive audio and text data never needs to leave the device.
The Shift Toward On-Device AI
The emergence of engines like MetalRT reflects a broader shift in AI infrastructure. For many years, most AI applications relied on cloud GPUs from companies such as Nvidia to run inference workloads. While powerful, cloud infrastructure introduces network latency, ongoing costs and potential privacy concerns.
At the same time, modern consumer processors have become dramatically more capable. Apple’s latest chips combine powerful GPUs with unified memory architectures optimized for machine learning workloads. As a result, tasks that once required remote servers can increasingly run locally on laptops and mobile devices.
RunAnywhere believes this shift will fundamentally reshape how AI systems are deployed. Instead of sending requests to remote servers, applications will increasingly run models directly on user devices. The company’s platform also includes deployment tools designed to manage AI models across fleets of devices, including version control, rollout policies and over-the-air updates.
Toward Real-Time Voice AI
MetalRT’s current release focuses on individual components such as language models, speech recognition and speech synthesis. The company’s broader goal, however, is to combine these capabilities into a fully integrated voice AI pipeline. RunAnywhere is developing a system that can listen, interpret and respond using natural speech entirely on-device, with MetalRT serving as the core inference engine.
The upcoming system will deliver the fastest voice AI pipeline available on Apple Silicon. Applications could include offline voice assistants, secure medical transcription tools, accessibility software that responds instantly to spoken commands and privacy-focused voice interfaces in regulated industries. Because the models run locally, these systems could function even without an internet connection.
The Future of AI May Be Local
MetalRT’s benchmarks suggest that the gap between cloud-based AI and on-device AI is shrinking quickly. With speech recognition hundreds of times faster than real-time, near-instant speech synthesis, and high-speed language model decoding, modern laptops are increasingly capable of running advanced AI assistants locally.
For developers, this shift could simplify infrastructure while reducing cloud costs. For users, it could lead to faster, more private and more reliable AI experiences. If engines like MetalRT continue improving at this pace, the next generation of AI systems may no longer rely on distant data centers. Instead, they may run directly on the devices people use every day.







